👨🏫 Porady
Playwright i wydajność testów REST API
canonical
Language
date
Oct 30, 2023
slug
playwright-rest-api-performance
author

status
Public
tags
Playwright
Automatyzacja
REST API
TypeScript
JavaScript
summary
Czy warto testować tylko REST API z Playwright? Mały test wydajności i porównanie z innymi narzędziami
type
Post
thumbnail

updatedAt
Oct 30, 2023 03:42 PM
category
👨🏫 Porady
W ostatnich miesiącach Playwright zyskuje coraz większą 🔗popularność.
Jest coraz częściej wykorzystywany w projektach, aby skutecznie i szybko automatyzować testy na różnych poziomach (modułowe, integracyjne, e2e, zarówno UI, jak i REST API).
Również ostatnio zauważyłem, że coraz częściej pojawiają się pytania:
Czy Playwright nadaje się również do pisania samych testów REST API?
Jak wypada jego wydajność w porównaniu z innym narzędziami?
Czy Playwright to dobry wybór w automatyzacji REST API? Może lepiej wykorzystać inne biblioteki?
Spodziewałem się wyników, jednak postanowiłem to sprawdzić na prostym przykładzie, aby mieć potwierdzenie w liczbach.
Aktywnie wykorzystujemy Playwright na co dzień w komercyjnych projektach do testów UI oraz REST API. Przygotowaliśmy o nim nowatorski Program, w którym poruszamy testy UI oraz API: 🔗https://jaktestowac.pl/playwright/
Z narzędzi Mocha i Supertest korzystamy w niektórych projektach, które wymagają jedynie testów REST API. Przygotowaliśmy również o tych narzędziach kurs automatyzacji testów, który wchodzi w skład Programu: 🔗https://jaktestowac.pl/api/
Ważne: Artykuł ten ma charakter poglądowy i ma na celu ogólnie wykazać, czy i jak bardzo Playwright jest wolniejszy niż dedykowane narzędzia do testów REST API w języku JavaScript/TypeScript😉
Pomiary zostały wykonane w warunkach domowych, które odbiegają od sterylnych warunków laboratoryjnych. Przez to nie udało się prawdopodobnie uniknąć wpływu takich czynników jak wpływ obciążenia dysku, CPU czy nierównomierne obciążenie testowanej aplikacji lub systemu.

Wykorzystane narzędzia
W testach wydajności porównałem miedzy sobą 2 zestawy bibliotek do testowania REST API:
- Playwright
- Mocha + Supertest
Całość bazowałem na narzędziach:
- JavaScript/TypeScript
- Node.js v18.17.1 - 🔗https://nodejs.org/en
System:
- Windows 10
Stworzyłem 2 projekty oparte o powyższe narzędzia.
Testy były uruchamiane bez zrównoleglania, które jest dostępne w obu tych narzędziach.
Projekt z Playwright
Pierwszy z nich zawierał w sobie:
- Playwright - framework, który umożliwia testowanie zarówno UI, jak i REST API - 🔗https://github.com/microsoft/playwright
- faker-js - do generowania losowych danych - 🔗https://www.npmjs.com/package/@faker-js/faker
Wersje:
- "@playwright/test": "1.39.0",
- "@types/node": "20.8.9",
- "@faker-js/faker": "8.0.2"
Komenda do uruchamiania testów:
npx playwright test
Projekt z Mocha+Supertest
Drugi projekt bazował na:
- Mocha - runner do testów, często wykorzystywany w testach jednostkowych, modułowych czy REST API - 🔗https://www.npmjs.com/package/mocha
- Supertest - jedna z najpopularniejszych bibliotek do komunikacji z REST API - 🔗https://www.npmjs.com/package/supertest
- faker-js - do generowania losowych danych - 🔗https://www.npmjs.com/package/@faker-js/faker
- chai - popularna biblioteka do asercji - 🔗https://www.npmjs.com/package/chai
Wersje:
- "@faker-js/faker": "8.0.2",
- "chai": "4.3.8"
- "mocha": "10.2.0",
- "supertest": "6.3.3"
Komenda do uruchamiania testów:
mocha --require hooks.js --timeout 10000
Typy testów
Każdy z tych projektów zawierał w sobie 1 identyczny test, który dotyczył aplikacji 🦎GAD. Jest to nasza autorska aplikacja, którą przygotowałem razem z Przemkiem, i którą wykorzystujemy w kursach do nauki automatyzacji. Aplikacja 🦎GAD jest lekką aplikacją napisaną w node.js i pozwala na testy UI oraz REST API.
Repozytorium aplikacji 🦎GAD znajdziesz tu: 🔗https://github.com/jaktestowac/gad-gui-api-demo
Projekt testu, który korzysta z REST API:
- pobranie zasobów (GET)
- sprawdzenie kodu odpowiedzi oraz liczby zwróconych elementów (czy jest ich więcej niż 1)
- autoryzacja użytkownika (POST)
- stworzenie zasobu (POST)
- sprawdzenie kodu odpowiedzi oraz zwróconych danych
Przeprowadzenie testów wydajności
Testy przeprowadziłem dla aplikacji uruchomionej:
- lokalnie
- na zewnętrznym serwisie (Glitch 🔗https://glitch.com/)
Testy zostały przystosowane, aby można było je uruchomić w pętli. Dla poszczególnych środowisk uruchomiłem następującą liczbę testów:
- lokalnie - 100 i 1000
- na zewnętrznym serwisie - 20 i 100
Przed każdym z zestawów testów:
- przywracałem aplikację i jej bazę danych do stanu bazowego, aby zmniejszyć wpływ setek zasobów, które zostały stworzone podczas testów,
- restartowałem testowaną aplikację.
Pomiar czasu
Na całkowity czas testów składają się w uproszczeniu dwa elementy:
- czas samego testu (przy większej liczbie testów stanowi on znaczą większość całkowitego zmierzonego okresu),
- czas dodatkowy, w skład którego wchodzi:
- czas uruchomienia danego narzędzia zanim zostanie uruchomiony test,
- czas pomiędzy testami,
- czas wygenerowanai podsumowania i zakończenia procesów.
Do pomiarów czasu trwania poszczególnych testów (jak i średniej) wykorzystałem moduł
perf_hooks, który jest wbudowany w node.js. Moduł ten pozwala na pomiary czasu pomiędzy zadanymi fragmentami kodu. Dla przykładu - ustawiając znaczniki np. przed i po teście jesteśmy w stanie zmierzyć czas trwania testu. Więcej: 🔗https://nodejs.org/api/perf_hooks.htmlW przypadku pomiaru całego uruchomienia testów (czas testów + czas dodatkowy) - tutaj bazowałem na informacjach, które otrzymuje się w konsoli, lub za pomocą narzędzia
Measure-Command (dostępne w PowerShell w Windows).Ważne: W poniższych pomiarach czas testów został uśredniony, przez co wynik można uznać za dość miarodajny. Jednak, aby jeszcze poprawić jakość wyników, należało by również otrzymać kilkadziesiąt pomiarów z czasu dodatkowego, które następnie należałoby uśrednić.
Dodatkowo warto pamiętać, aby przeanalizować otrzymane pomiary. Wartości, które bardzo odbiegają od średniej, można uznać za błąd gruby, a następnie można je odrzucić z pomiarów.
W otrzymanych wartościach nie stwierdziłem występowania wartości typu błąd gruby.

Wyniki
Do dokładniejszych pomiarów, wliczających czas uruchomienia runnerów, użyłem polecenia:
Measure-Command { start-process npm 'run test' -wait -NoNewWindow }Dla 100 testów lokalnie
🎭Playwright
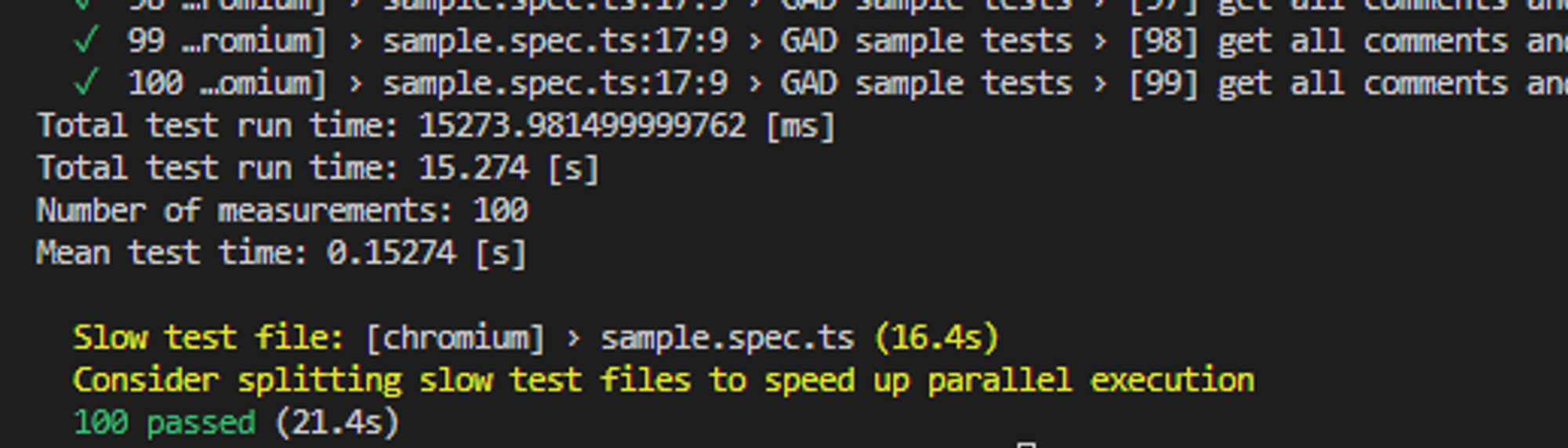
Wyniki otrzymane z Measure-Command - wynik całkowity 25.2s:
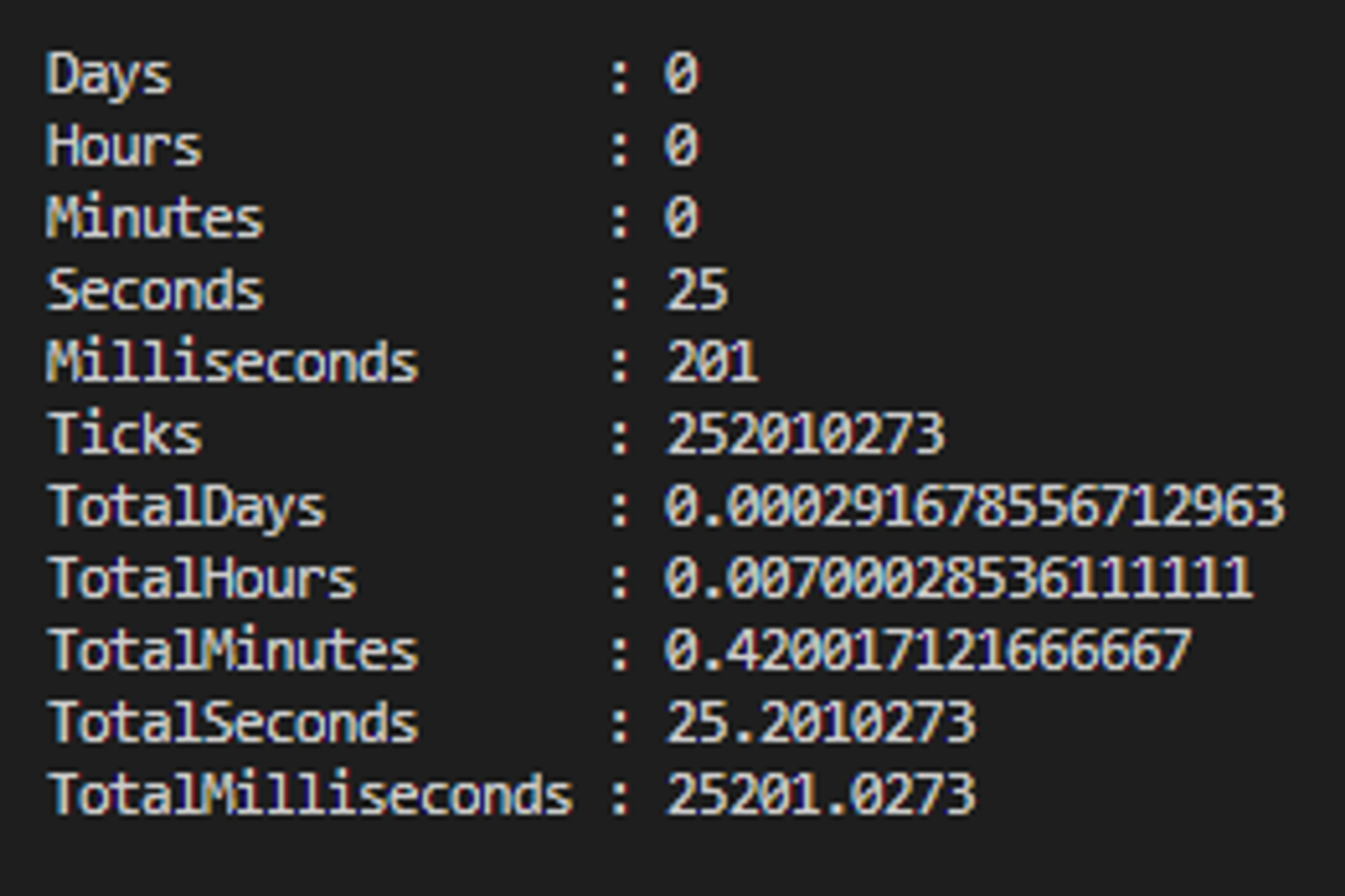
Ważne: Co znaczą poszczególne czasy?
- Total test run time - całkowity czas trwania testów (pomijając czas dodatkowy - czyli pomiędzy testami, czy na początku przy rozruchu test runnera)
- Mean test time - średni czas wykonania jednego testu
Wyniki otrzymane z Measure-Command:
- TotalSeconds - całkowity czas trwania uruchomienia testów - wraz z rozruchem test runnera, czasem między testami i czasem potrzebnym na wygenerowanie podsumowania
Zauważ, że runner przedstawia również czasy 16.4s oraz 21.4s. Są one zbliżone do wyników otrzymanych z perf_hooks oraz Measure-Command. Jednak z racji, że Mocha w inny sposób raportuje wyniki, to te 2 czasy pominiemy w porównaniach, aby wszystko uspójnić do perf_hooks oraz Measure-Command.
☕Mocha+supertest
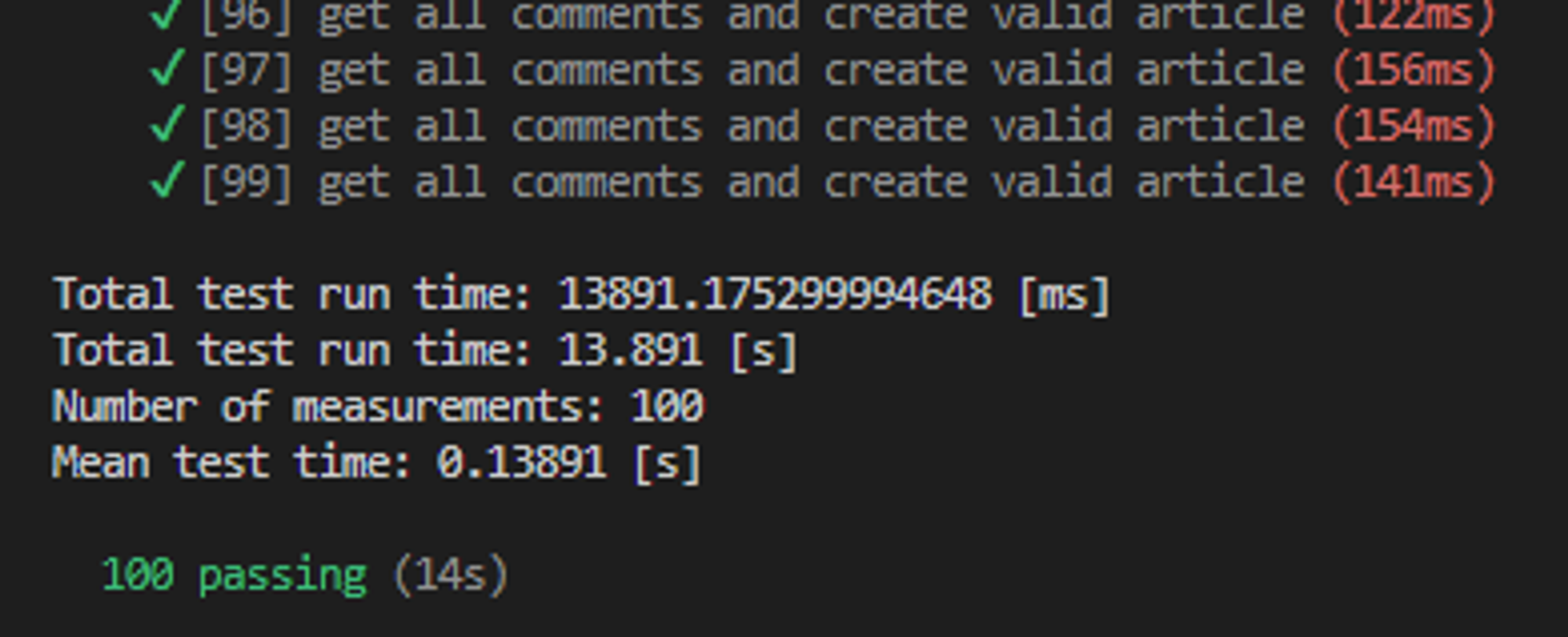
Wyniki otrzymane z Measure-Command - wynik całkowity 18.2s:
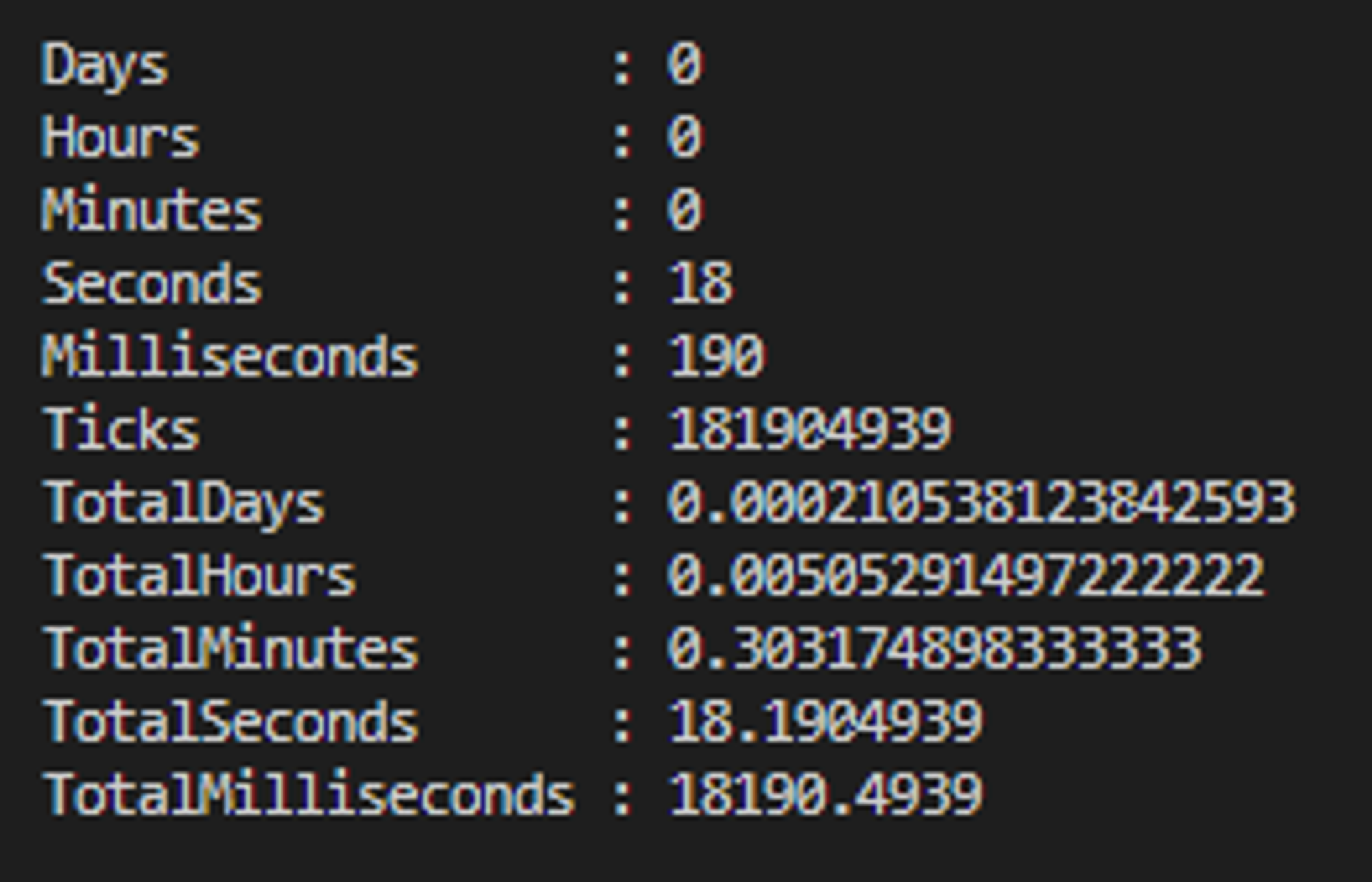
Dla 1000 testów lokalnie
🎭Playwright
"totalTime [ms]": 179815.77940004691,
"totalTimeRounded [s]": 179.816,
"totalTimeRounded [min]": 2.98,
"numberOfTests": 1000,
"meanTestTime": 0.179816
Wyniki otrzymane z Measure-Command - wynik całkowity 201.3s:
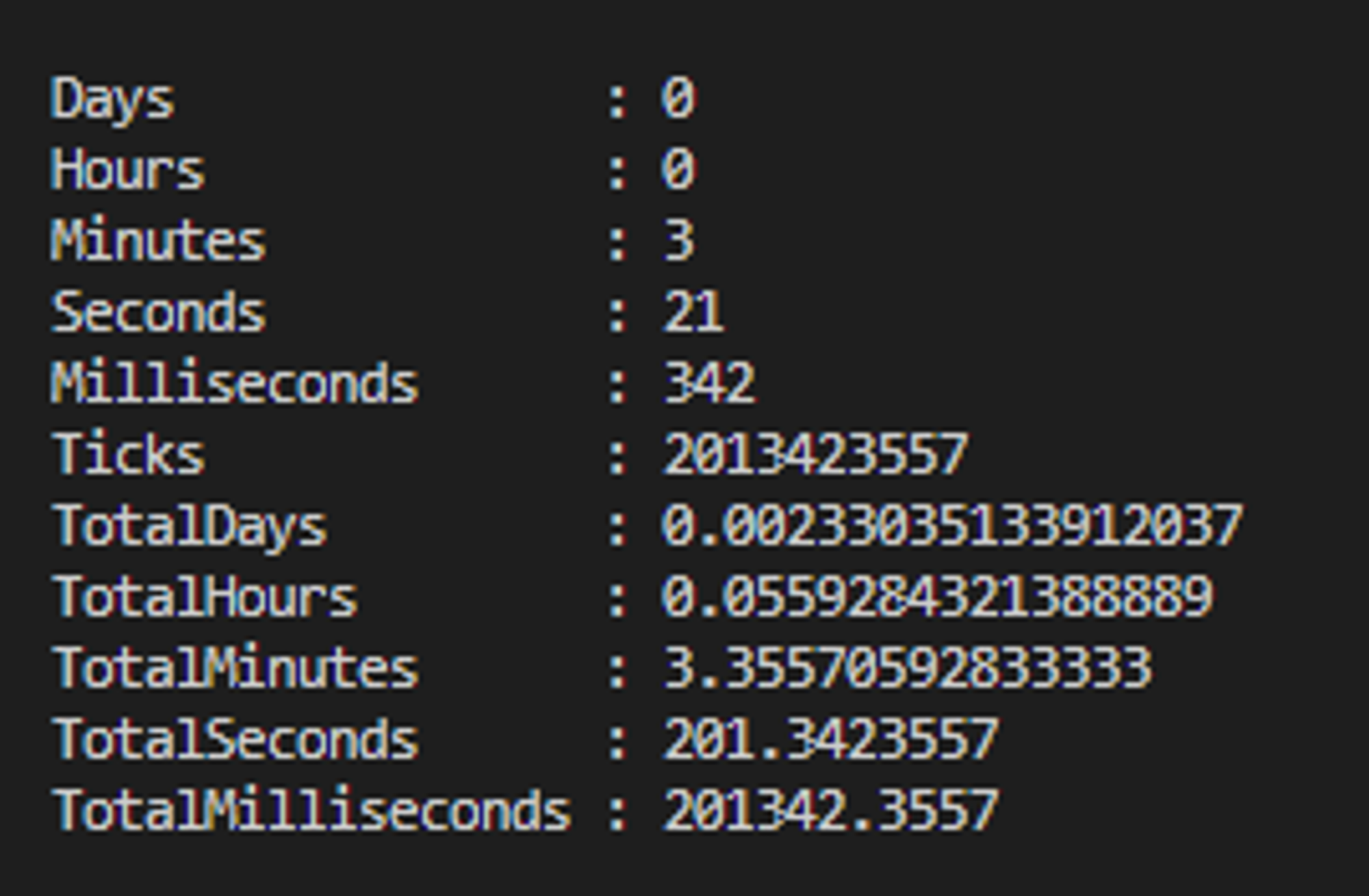
☕Mocha+supertest
"totalTime [ms]": 165929.16269998625,
"totalTimeRounded [s]": 165.929,
"totalTimeRounded [min]": 2.76,
"numberOfTests": 1000,
"meanTestTime": 0.165929
Wyniki otrzymane z Measure-Command - wynik całkowity 170.7s:
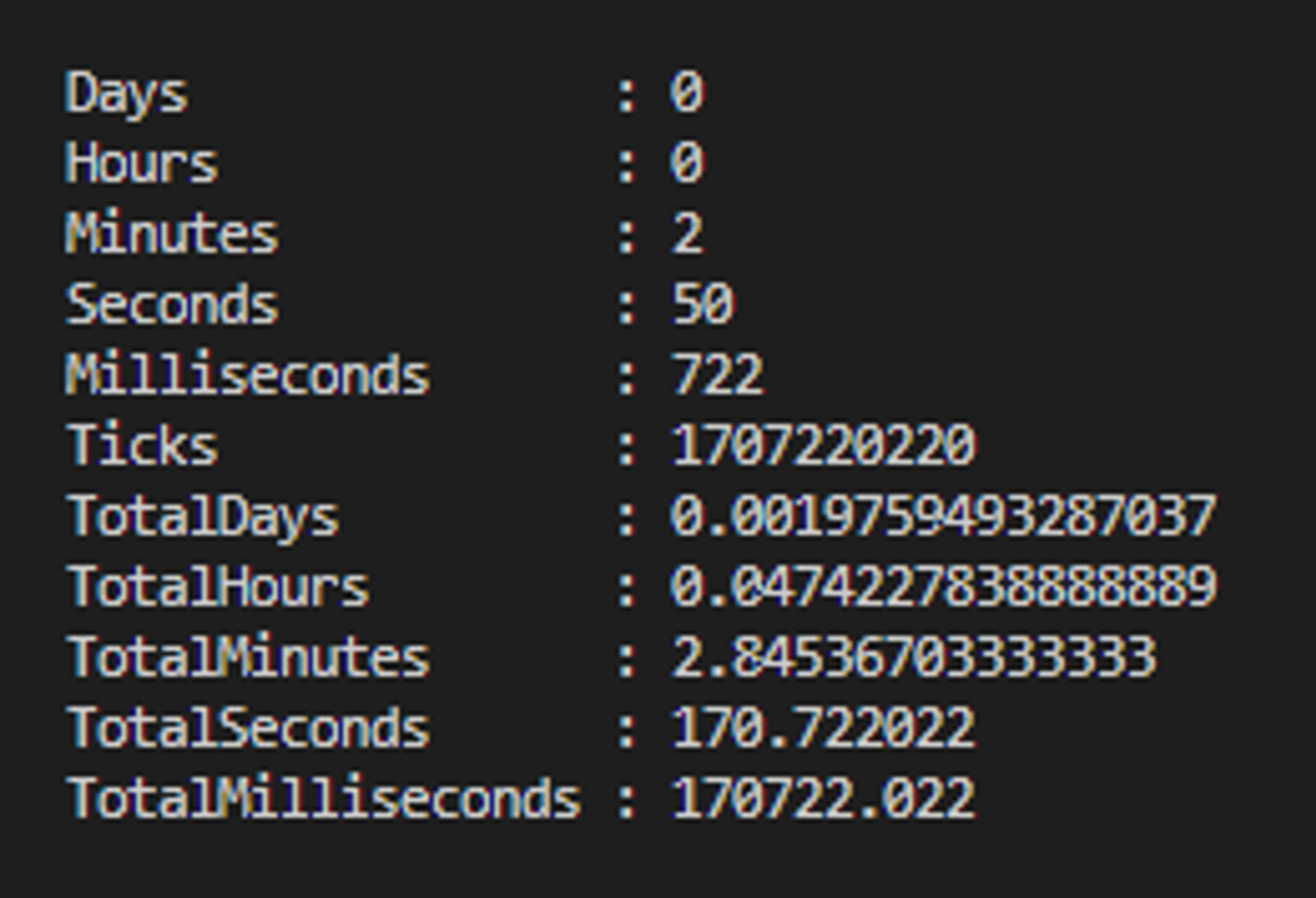
Dla 20 testów aplikacji w serwisie Glitch
🎭Playwright
"totalTime [ms]": 42998.682200003415,
"totalTimeRounded [s]": 42.999,
"numberOfTests": 20,
"meanTestTime": 2.14995
Wyniki otrzymane z Measure-Command - wynik całkowity 52.5s:
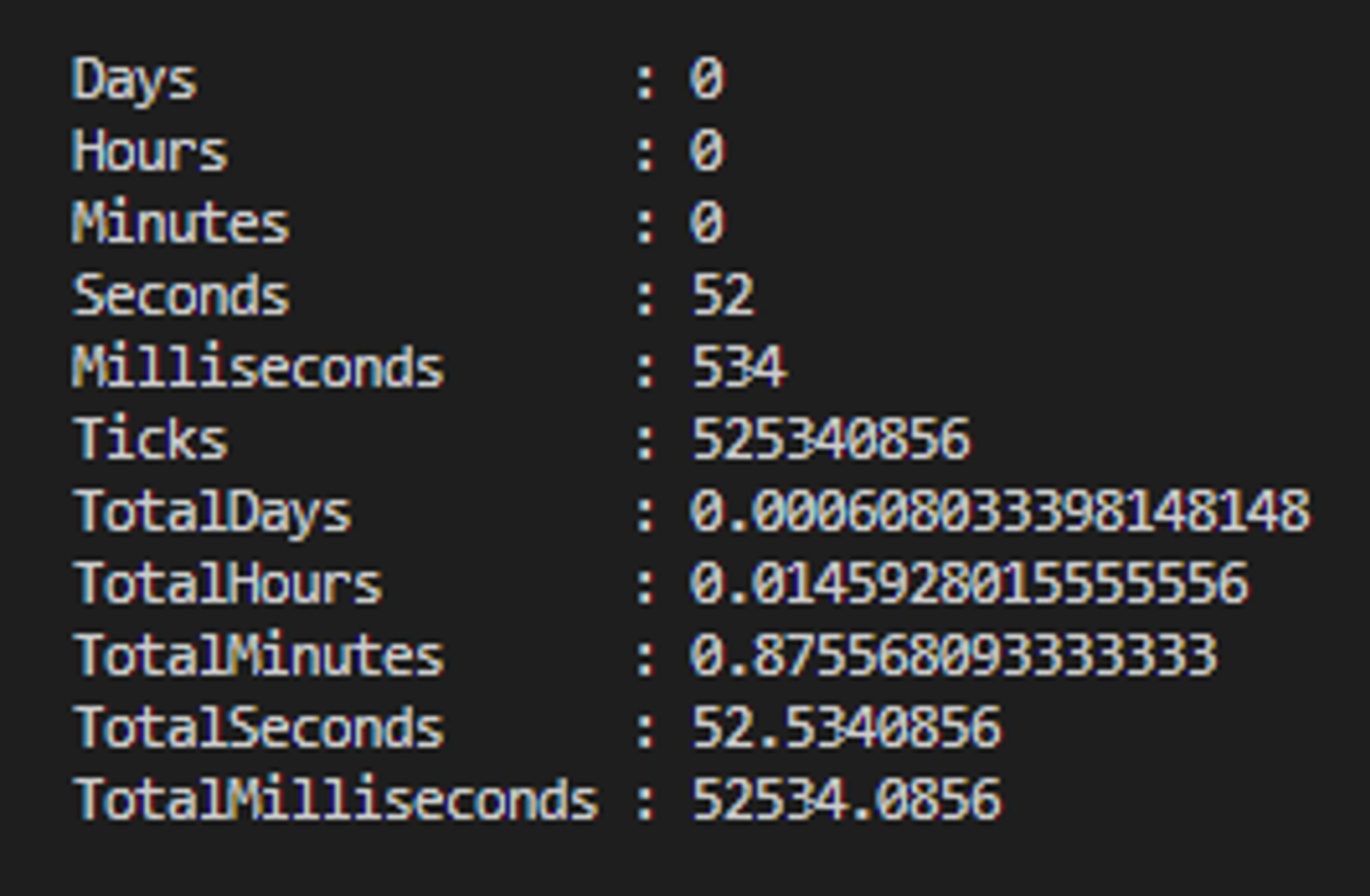
☕Mocha+supertest
"totalTime [ms]": 42105.03170000017,
"totalTimeRounded [s]": 42.105,
"numberOfTests": 20,
"meanTestTime": 2.10525
Wyniki otrzymane z Measure-Command - wynik całkowity 46.6s:
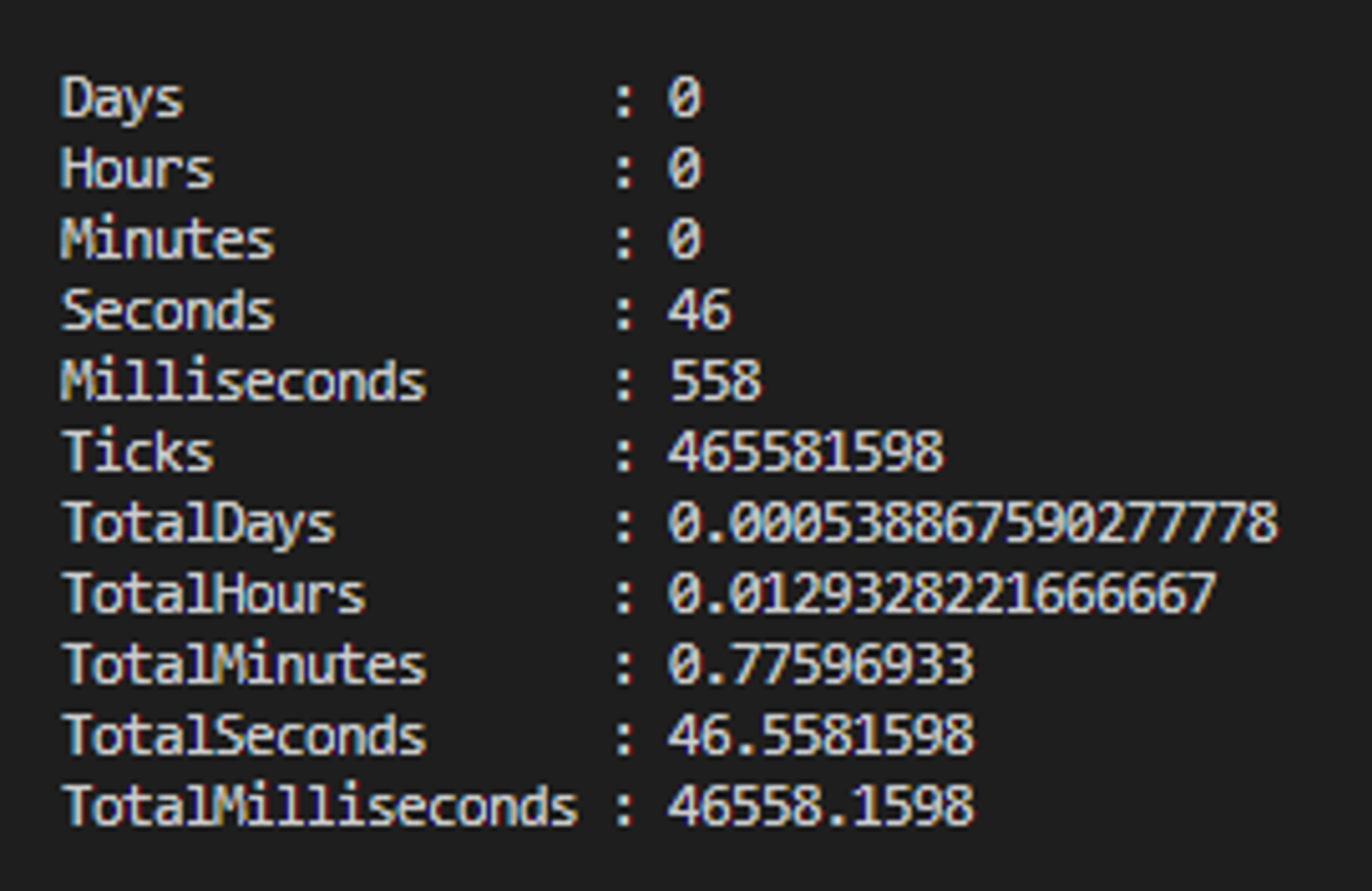
Dla 100 testów aplikacji w serwisie
🎭Playwright
"totalTime [ms]": 209659.00309997052,
"totalTimeRounded [s]": 209.659,
"totalTimeRounded [min]": 3.49,
"numberOfTests": 100,
"meanTestTime": 2.09659
Wyniki otrzymane z Measure-Command - wynik całkowity 221.4s:
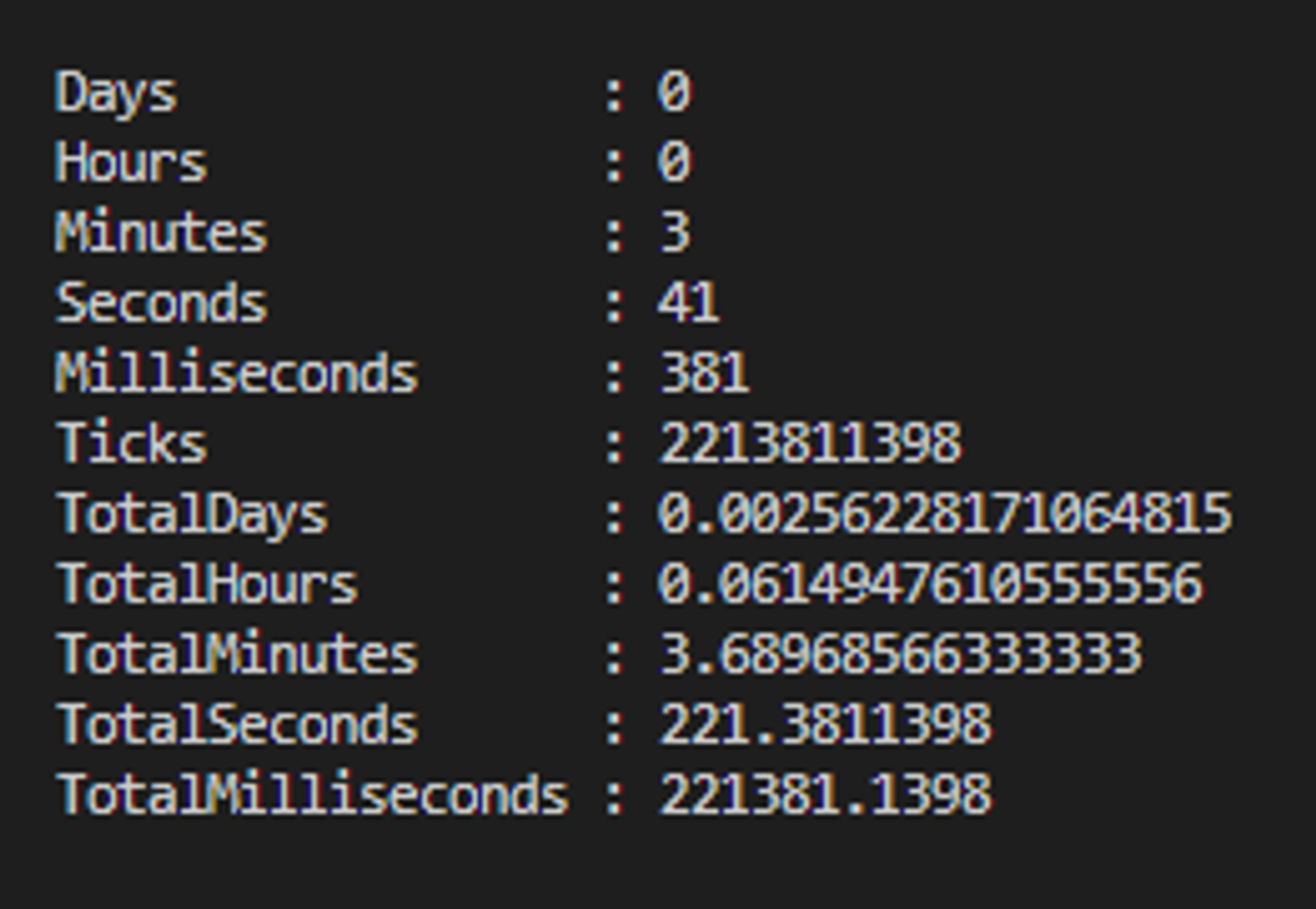
☕Mocha+supertest
"totalTime [ms]": 207580.64369999245,
"totalTimeRounded [s]": 207.581,
"totalTimeRounded [min]": 3.45,
"numberOfTests": 100,
"meanTestTime": 2.0758099999999997
Wyniki otrzymane z Measure-Command - wynik całkowity 212.3s:
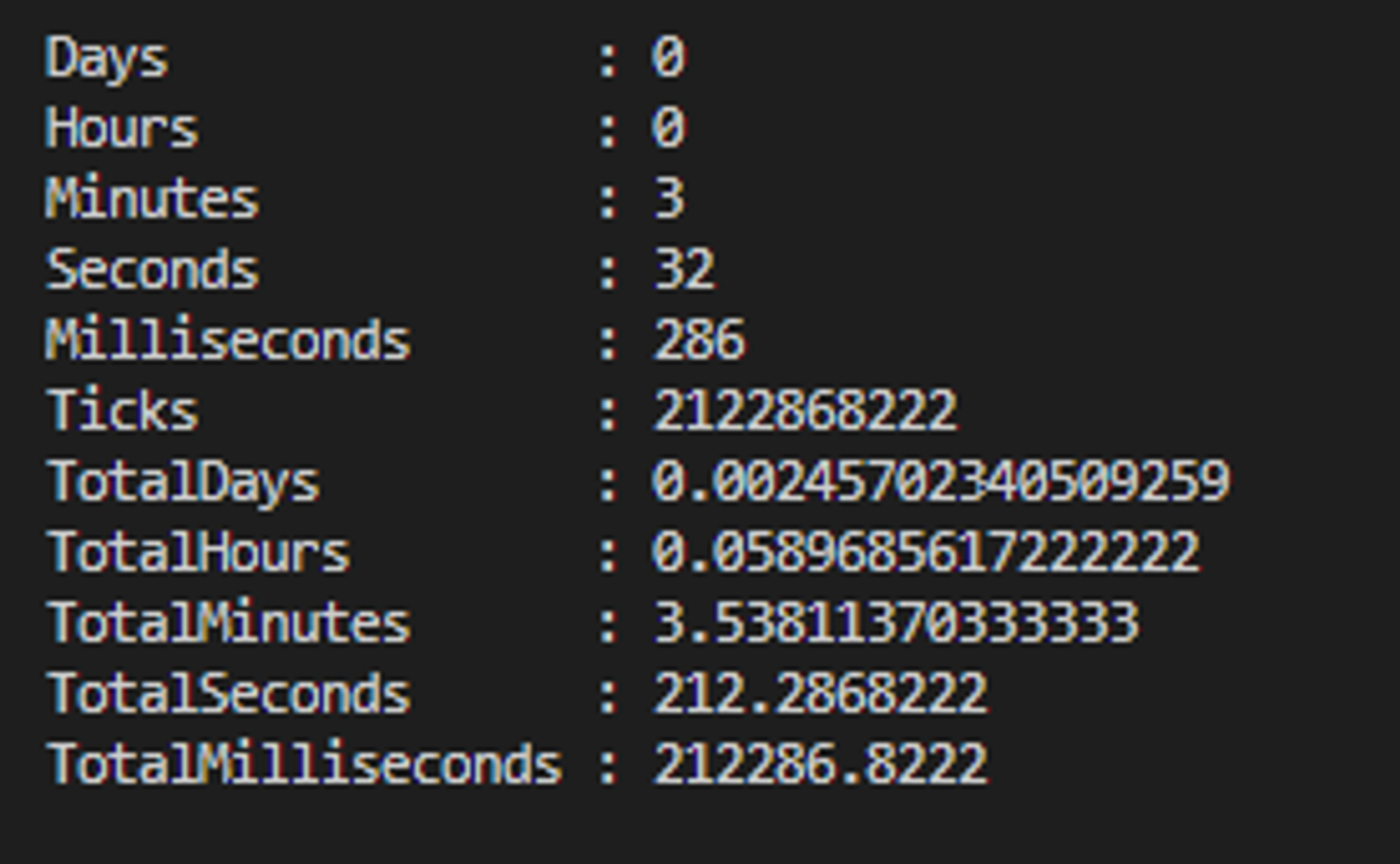
Podsumowanie i wnioski
Na tym prostym przykładzie widać, że w przypadku wykonywania testów Playwright jest niewiele wolniejszy niż Mocha+Supertest.
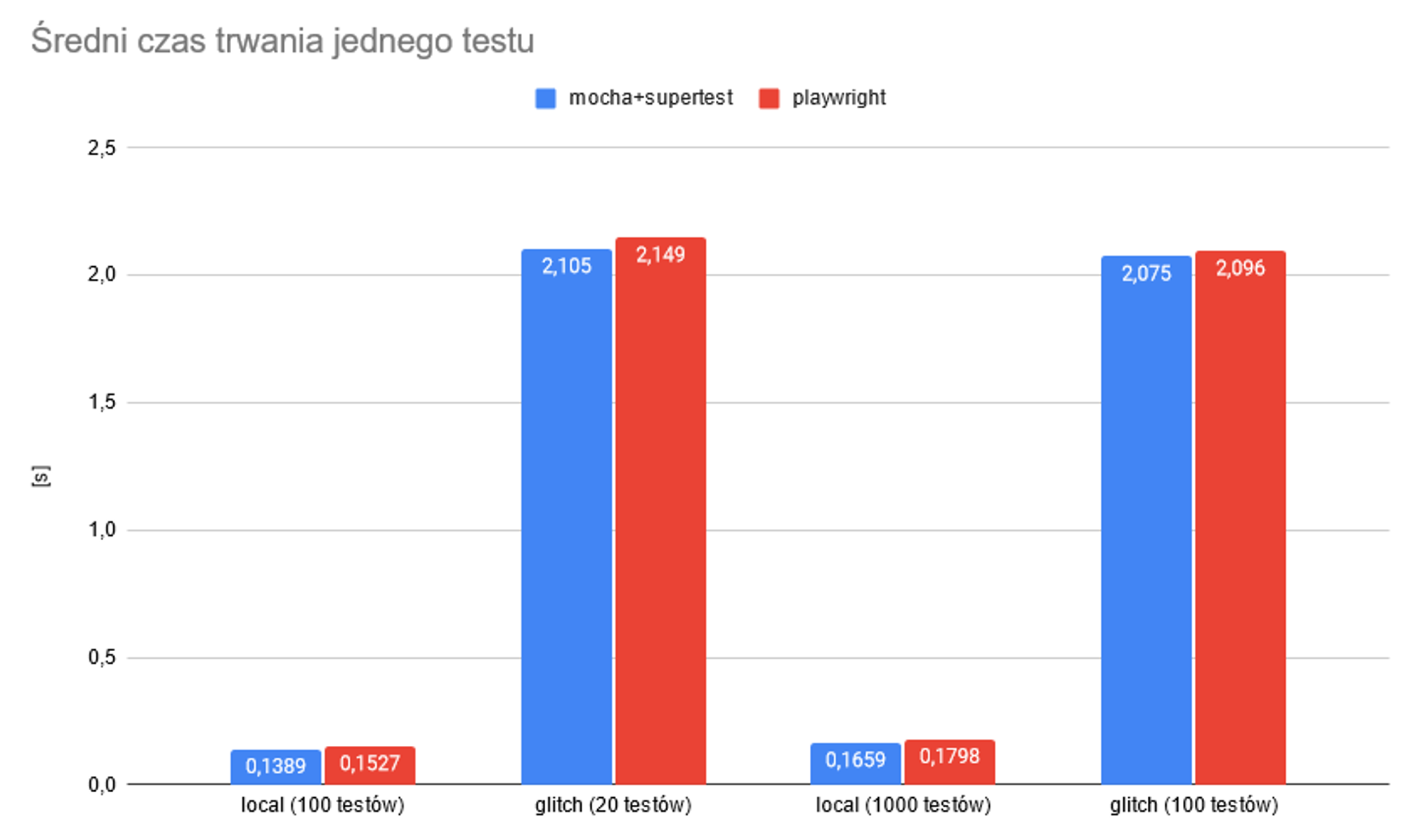
Średni czas trwania jednego testu w Playwright jest tylko odrobinę dłuższy (o kilka procent) od testu z Mocha i Supertest.
Pozostaje czas dodatkowy (przed, pomiędzy i po testach), który nie był liczony przez perf_hooks.
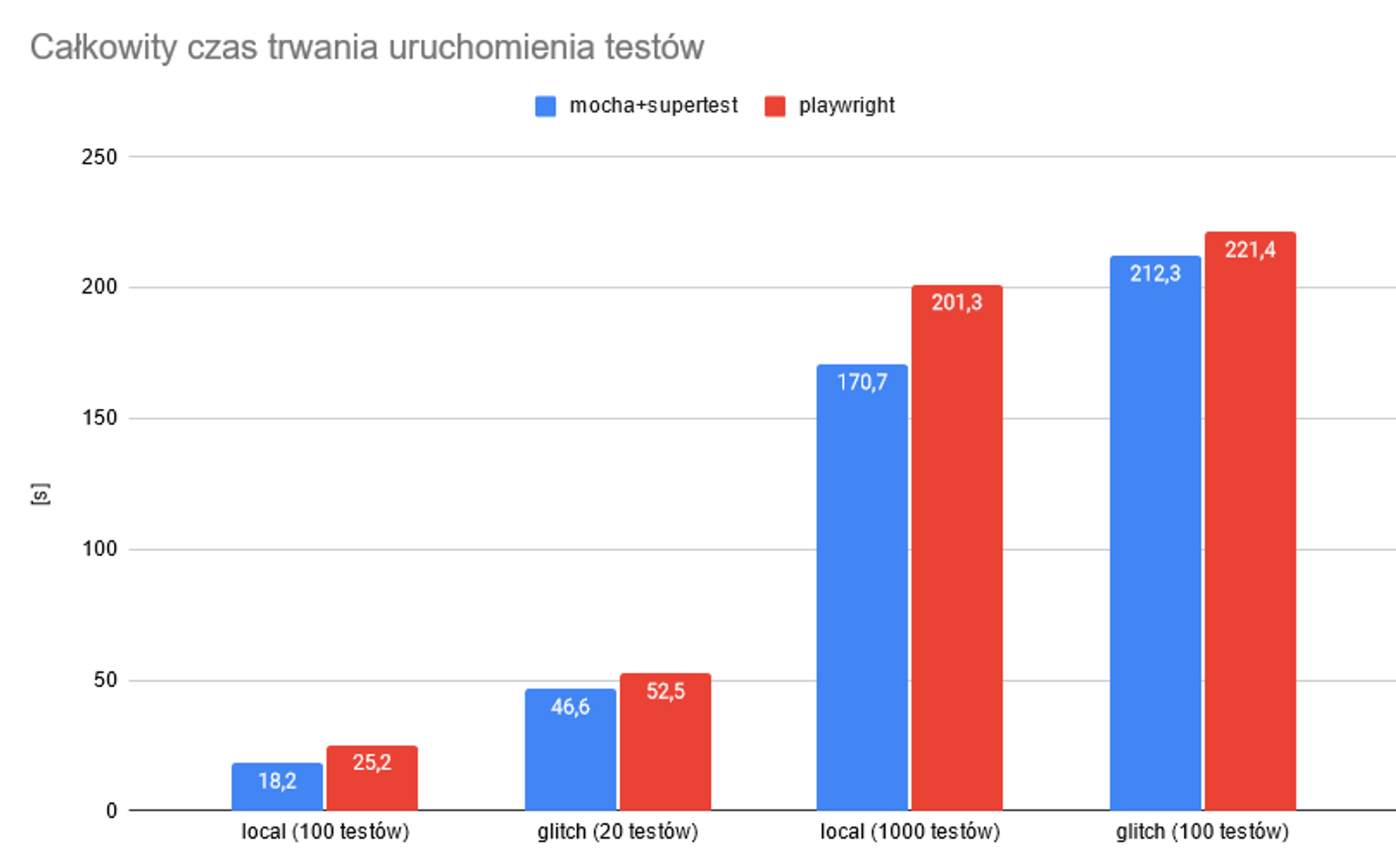
Na powyższym wykresie widać, że Playwright potrzebuje nieco więcej czasu - 4-10s przy 100 testach i ok. 20s przy 1000 testów. Prawdopodobnie jest to związane z elementami frameworka, które muszą być inicjalizowane między testami (np. fixtures, context etc.).
Zatem…
Czy warto stosować Playwright w testach REST API?

Myślę, że pomimo nieznacznie dłuższego czasu trwania testów nie ma jednoznacznej odpowiedzi. Oba narzędzia wykazały zbliżony czas wykonywania testów. Ich użycie zależy od kontekstu, potrzeb i przyszłości projektu.
Jeśli w projekcie testuje się tylko i wyłącznie REST API - to prawdopodobnie lepszym rozwiązaniem będzie rozwiązanie jak Mocha+Supertest. W tym założeniu należy pamiętać, że późniejsza migracja lub wprowadzenie testów UI może być bardzo kosztowane.
Natomiast jeśli w projekcie planowane są w przyszłości testy UI - to myślę, że od razu można wykorzystać Playwright. Dzięki temu łatwiej będzie wprowadzić testy UI oraz skorzystać z dobrodziejstw REST API przy automatyzacji testów e2e/integracyjnych bazujących na UI.
Jeśli natomiast wskazane tutaj czasy są akceptowalne dla Ciebie - możesz wykorzystać z powodzeniem Playwright, jako narzędzie do testów REST API. Jego niewątpliwą zaletą jest bardzo łatwa rozszerzalność o nowe moduły - bez problemu dodasz do niego moduły Supertest, Mocha, Faker czy inne, które potrzebujesz wykorzystać w swoich testach.
Warto tutaj wspomnieć o wadach i zaletach tych podejść.
✅Zalety Playwright, które są dostępne od razu z tym narzędziem:
- generowanie różnych typów raportów
- odrobinę szybsze wpięcie w proces CI
Mocha również oferuje te funkcje za pomocą dodatkowych wtyczek.
✅Zalety Mocha + Supertest:
- dojrzałe i rozbudowane narzędzia z konkretnym przeznaczeniem, które w niektórych przypadkach mogą oferować znacznie więcej niż Playwright (poczytaj poniżej👇)
Testowanie REST API za pomocą Playwright oraz zestawienie go z innymi narzędziami opisaliśmy w poście: 🔗https://playwright.info/playwright-rest-api-testing-narzedzia-i-biblioteki
Zachęcam Cię do dokładnego przemyślenia architektury swoich testów, wzięcia pod uwagę różnych rozwiązań i narzędzia, oraz rozpisania ich wad i zalet, na podstawie których dokonasz wyboru dostosowanego do potrzeb swoich i projektu😉
Co można zrobić, aby jeszcze przyśpieszyć testy?
Możemy je zrównoleglić!😉
W Playwright jest to dosyć proste - wystarczy w konfiguracji zmienić wartość dla workers. Jest to mechanizm wbudowany w tym narzędziu - 🔗https://playwright.dev/docs/test-parallel
W narzędziu Mocha od wersji v8.0.0 również został wprowadzony mechanizm zrównoleglania testów - 🔗https://mochajs.org/#parallel-tests
W każdym z powyższych przypadków pamiętaj, podczas projektowania testów uwzględnić potrzebę zrównoleglania. Wtedy trzeba uważać na współdzielenie zasobów między testami😉

Zasoby zewnętrzne
Polecane linki i materiały:
- Repozytorium z całym kodem użytym w pomiarach: 🔗https://github.com/jaktestowac/performance-test-playwright-rest-api-vs-mocha-supertest
- Aplikacja 🦎GAD: 🔗https://github.com/jaktestowac/gad-gui-api-demo
- Glitch: 🔗https://glitch.com/